پشتیبانی از دانلود های ناموفق
پاورپوینت ریشه یابی کلمات فارسی |Origins of Farsi words


خرید و دانلود آنی
شماره پشتیبانی
09103705578
ریشه یابی کلمات فارسی |Origins of Farsi words
ریشه یابی کلمات فارسی این جزوه را امروز می خواهیم در سایت دانشکده ها برای دانشجویان عزیز قرار دهیم
در 21 اسلاید زیبا با فرمت پاورپوینت جمع آوری شده است.
این مقاله بطور نمونه قسمتی از متن را خواهیم گذاشت.
انواع الگوریتم های ریشه یابی
الگوریتم های مبتنی بر دیکشنری : کاملترین الگوریتمهای ریشه یابی هستند. مشکلاتی نظیر :
.1قابلیت گسترش پایین (no scalability)
.2ناتوانی در دسته بندی کلمات در گروه های معنایی همسان
.3درجه زمانی و مکانی بسیار بالا
الگوریتم های مبتنی بر قانون : این الگوریتمها، بر روی به دست آوردن ریشه ی کلمات از طریق تعدادی قوانین از پیش تعیین شده کار می کنند.
.1قوانین موجود ساختارهای زبانشناسی نیستند.
.2مشکلات روش قبل را ندارند.
.3از لحاظ مؤفقیت از درصد پایینی برخوردار هستند.
.4از این دسته الگوریتمها می توان به الگوریتمهای معروف Porter و Lovins و Krovetz… بر روی زبان انگلیسی و الگوریتم ریشه یابی کاظم تقوی و … بر روی زبان فارسی اشاره کرد.
ریشه یابی کلمات فارسی
ریشه یابی کلمات فارسی بررسی الگوریتم porter :در هر برنامه جداسازي پسوند در سيستم هاي IR دو مورد بايستي مد نظر باشد.
اول آنكه در سيستم هاي IR پسوندها به هدف افزايش كارائي سيستم حذف مي شوند و نه به لحاظ عمليات زبانشناسي. اين بدان معني است كه لزومي ندارد تا بفهميم تحت چه شرايطي يك پسوند بايستي حذف گردد.
نكته دوم آن است كه با استفاده از روشي كه توضيح داده خواهد شد؛ يعني با استفاده از ليست پسوندها با قوانين اِعمال متعدد، ضريب موفقيت در حذف پسوندها جدا از آنكه اين پردازش چگونه ارزيابي شود، مطمئناً كمتر از 100 درصد خواهد بود.
ریشه یابی کلمات فارسی ريشه ياب پورتر ريشه ياب كاهش دهندة ادغامي براي زبان انگليسي است كه توسط مارتين پورتر در دانشگاه كمبريج در سال 1980 ارائه شد.
اين ريشه ياب بصورت مرحله اي(5 مرحله كه در هر مرحله قوانين خاصي اِعمال مي شود) و خطي می باشد که در ادامه به این مراحل اشاره می کنیم. در هر مرحله عملیات کاهش یا افزایش روی کلمات صورت می گیرد.
در زبان انگليسي يك حرف بي صدا(Consonant) در يك كلمه حرفي غير از A,E,I,O,U و Y بعد از يك حرف صدادار است.
(واقعيت آن است كه تعريف حرف بي صدا بصورت بازگشتي در اينجا باعث مبهم شدن تعريف حرف بي صدا نمي شود). بنابراين در TOY حروف بي صدا T و Y هستند و در SYZYGY حروف بي صدا S و Z و Gميباشند.
CVCV … C
CVCV … V
VCVC … C
VCVC … V
[C]VCVC … [V]قوانين براي حذف پسوند در فرم زير نمايش داده مي شود:
(condition) S1-> S2كه به معناي آن است كه اگر كلمه اي با پسوندِ S1 پايان بگيرد و ريشة ماقبل S1 شرطِ(condition) داده شده را ارضا كند، S1 با S2 جايگزين مي شود.
*S: ريشه با حرفِ S پايان مي گيرد(همچنين براي ساير حروف).
*v*: ريشه شامل حرف صدادار است.
*d: ريشه با دو حرف صدادار يكسان پايان مي گيرد(مثل TT وSSو…).
*o: ريشه با cvc پايان مي گيرد بطوريكه دومين c ،حروفِ W،X ياY نيست.(مثل-HOP,-WIL).
بررسی الگوریتم porter – مراحل روش
در مرحله اول بیشتر با قسمت سوم افعال و صورت جمع کلمات سروکار داریم مثل:
SSES à SS caresses à caress
IES à I ponies à poni
SS à SS caress à caress
…
در مراحل 2 و3 و 4 هم به صورت مشابه قوانین مختلفی استفاده می شود تا به ریشه مورد نظر نزدیک تر شویم مثل :
2 : (m>0) ATIONAL à ATE relational à relate
(m>0) TIONAL à TION conditional à condition
3: (m>0) ATIVE à formative à form
(m>0) ALIZE à AL formalize à formal
4 : (m>1) IBLE à defensible à defens
(m>1) ATE à activate à activ
…
تا اينجا تمامي پسوندها حذف شده است و آنچه كه مانده كمي از مراحله تصفيه (مرحله 5) است. در این مرحله هم عملیاتی نظیر قوانین زیر صورت می گیرد.
(m>1) E -> probate -> probat
…
بررسی الگوریتم porter – فلوچارت
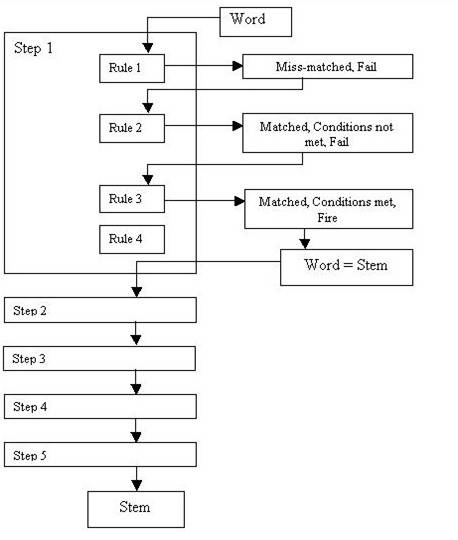
بررسی الگوریتم porter :
در الگوریتم porter هیچ توجه ای به پیش وند ها نمی شود : باعث می شود که نتایج کمی نادرست باشد ولی در عمل اين مسئلة چنداني نيست چونكه وجود پيشوند احتمال كاهشها و ادغامهاي نادرست را كاهش مي دهد.
مزایای عمده این روش :
.1این الگوریتم کوتاه ( كمتر از 400 خط كد به صورت BCPL) و سریع می باشد. (واژگان با 10000 كلمة مختلف را در 8.1 ثانيه بر روي IBM 370/165 در دانشگاه كمبريج پردازش كرده است).
.2ساده و کارا می باشد.
.3قابلیت انعطاف دارد.
اولین کسی باشید که دیدگاهی می نویسد “پاورپوینت ریشه یابی کلمات فارسی |Origins of Farsi words”
محصولات مرتبط

20,000 تومان
پاورپورنت درمورد تئوری پایه عمل دستگاه گردش خون این پاورپورنت درمورد تئوری پایه عمل دستگاه گردش خون 17 اسلاید تئوري پايه عمل دستگاه گردش خون, کار دستگاه گردش خون ,کار دستگاه گردش خون چیست,کار دستگاه گردش خون در بدن, طرز کار دستگاه گردش خون,نحوه کار دستگاه گردش خون, چگونگی کار دستگاه گردش خون,روش کار دستگاه گردش خون,تئوری
20,000 تومان
پاورپوینت دانلود جزوه هیداتیدوز در 43 اسلاید پاورپوینت تهیه و تنظیم شده است مناسب دانشجویان عزیز که برای دانلود این تحقیق میبایست فایل مورد نظر را خریداری کنید تا بتوانید این مقاله را بطور کامل دانلود کنید.ما بطور نمونه قسمتی از متن این پاورپوینت را در قسمت پایین برای شما کاربران دانشکده ها قرار خواهیم

20,000 تومان
درمورد گازها و تئوری جنبش مولکولی گازها و تئوری جنبش مولکولی این پاورپوینت در مورد گازها و تئوری جنبش مولکولی که در ۲۴۵اسلاید شامل اهداف رفتاری بیان قانون ایده ال,قانون بویل ,در یک مقدار معین از یک گاز,نقطه سه گانه آب,ترمودینامیکی و دمایی,گیلوساک در حجم ثابت, شیب منحنی های حاصل در دمای صفر درجه

20,000 تومان
پاورپوینت دانلود مراكز رشد و راهکارهای محصول محوری دستاوردهای پژوهشی مراكز رشد (Incubator) و راهکارهای محصول محوری دستاوردهای پژوهشی ارایه دهنده: حسن علم خواه مدیرعامل و هیات مدیره موسسه دارایی های فکری و فناوری مدرس مشاور تجاری سازی دانشگاه صنعتی امیرکبیر کارگزار مالکیت فکری پارک فناوری پردیس (ریاست جمهوری) مرکز رشد سلامت دانشگاه علوم پزشکی

20,000 تومان
پاورپوینت درمورد اپيدميولوژي اچ ای وی این پاورپوینت درمورد اپيدميولوژي اچ ای وی در 47 اسلاید جذاب و آماده برای دانشجویان که شامل: تعداد افراد مبتلا در زمان (تا3سال پيش),همه گيري جهاني HIV/AIDS از سال 1990تا 2005,ميزان اشغال تخت هاي بيمارستاني بدليل ايدز در زيمبابوه, درصد كل بودجه وزارت بهداشت,تعداد كودكان به جاي مانده از ايدز,كاهش

20,000 تومان
پاورپوینت دانلود جزوه تئوری الاستیسیته تئوری الاستیسیته Theory of Elasticity این پست درمورد جزوه تئوری الاستیسیته که در یک فایل پاورپوینت آماده شده است تعداد اسلاید ۱۶۲ می باشد مناسب برای دانشجویان عزیز برای دانلود جزوه تئوری الاستیسیته باید یه مقدار هزینه ای پرداخت نمایید که بعد از خرید اینترنتی لینک دانلود برای شما نمایان

20,000 تومان
پاورپوینت درمورد ذرات نانو و نانوفناوری در نمک زدایی موضوع: ذرات نانو و نانوفناوری در نمک زدایی رویا منصوری شرکت مهندسی آب و فاضلاب کشور تحقیقات و فناوری پاورپوینت درمورد ذرات نانو و نانوفناوری در نمک زدایی معضلات آب در سطح جهان درمورد ذرات نانو و نانوفناوری در نمک زدایی آب شیرین بعد از نفت
20,000 تومان
پاورپوینت اپیدمیولوژی بیماری های واگیردار این پاورپوینت اپیدمیولوژی بیماری های واگیردار در ۱۴۵اسلاید زیبا و جذاب آماده برای دانشجویان که شامل:تعــریف اصطلاحات رایج اپیدمیولوژیک, عفونت (Infection),عفونت تحت بالینی,بیماری(Dis – Ease),ابتلا (Morbidity),بیماری عفونی (Infectious Disease),بیماری قابل سرایت( (Communicable Disease, بیماری مسری (Contagious Disease),دوره های یک بیماری,آلودگی عفونی (Contamination),آلودگی غیرعفونی (Pollution),آلودگی انگلی (Infestation), عفونت های فرصت طلب (Opportunistic

نقد و بررسیها
هنوز بررسیای ثبت نشده است.